
Les données No SQL (XML, Json, Avro, Copybook Cobol…) avec simplicité
La gestion de fichiers de données est une problématique d'actualité, notamment à l'époque du Big Data et du NoSQL.
De plus en plus de données sont stockées dans des structures fichiers plats ou fichiers hiérarchiques (Json, XML,…), dont certaines très spécifiques au domaine du Big Data comme Avro. Ces structures hiérarchiques sont soit disponibles directement dans le système de fichiers (Windows, Linux, Hdfs, Amazon, Azure…) soit encapsulées dans une technologie tierce (Elastic Search, Mongo DB, Big Query, Snowflake, Teradata…).
Découvrez les fonctionnalité de Stambia qui permettent d'accélérer les projets nécessitant l'usage de fichiers et de structures hiérarchiques.

XML, JSON, Avro… Pourquoi est-ce parfois compliqué ?
Des solutions ETL traditionnelles adaptées aux formats simples
Les solutions traditionnelles d'intégration de données ont très souvent été conçues pour des données au format tabulaire.
La gestion de données hiérarchiques est réalisable mais coûteuse en terme de temps de développement et parfois peu efficace en terme de performance.
Il n'est par rare de perdre beaucoup de temps et d'énergie dans des projets manipulant de simples données hiérarchiques (fichiers en provenance de gros systèmes, fichiers avec Copybook Cobol, données NoSQL comme JSON ou Avro, données en provenances de services web en XML, etc.).

Des problématique de volume de données

Les choses se compliquent souvent lorsque le volume de données augmente.
Deux cas de figure peuvent se présenter :
- Chaque fichier est de taille importante et nécessite d'augmenter de manière importante la puissance machine, notamment la mémoire, afin que le fichier puisse être lu sans défaillance de l'ELT.
- Le nombre de fichiers est important et les mécanismes de parallélisassion ne sont pas efficaces. De ce fait, le temps nécessaire au traitement d'un batch de fichiers peut se révéler rédhibitoire ou pénalisant pour les équipes d'exploitation.
XML, JSON... Des formats de données pas toujours facile à comprendre
Enfin, tout le monde n'est pas un spécialiste des technologies hiérarchiques, particulièrement les Web Services ou les formats très spécifiques comme Avro ou Json.
La manipulation de telles structures avec des solutions traditionnelles ou Open Source peut nécessiter des compétences techniques non négligeables et ralentir le temps de réaction par rapport à une demande métier.
Chaque petite particularité (un type de données non compris ou un format spécifique du fichier) peut faire perdre énormément de temps.

Comment Stambia ETL gère les structures hiérarchiques ?
1. Simplifier l'usage des données hiérarchique avec Stambia ETL
La Représentation des données par les méta-données
La gestion des fichiers dans Stambia est simple.
De nombreux assistants permettent d'aider l'utilisateur dans la récupération des métadonnées. Ils sont adaptés à chaque technologie, prenant en compte chacune des spécificités.
Lorsque les technologies le permettent, Stambia proposera d'utiliser les standards de reverse engineering spécifiques (XSD, DTD, WSDL, etc.). Lorsque ce n'est pas le cas (format plus libre), L'assistant proposera d'utiliser des données d'exemple afin de récupérer le maximum d'information.
A tout moment, l'utilisateur pourra corriger et ajouter ses propres informations afin d'avoir une description des objets qui soit la plus fidèle aux données qu'il aura à traiter.
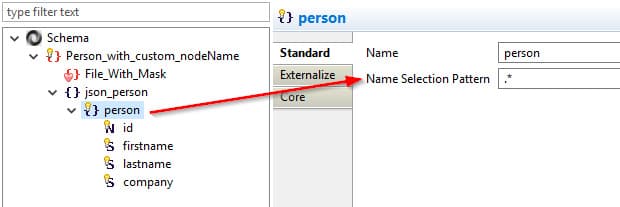
L'exploration des données hiérarchiques
Le Designer Stambia permet de lire directement les données hiérarchiques de type JSON ou Avro, avec un éditeur spécialisé.
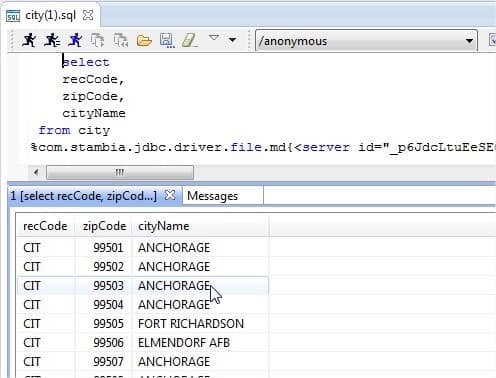
Lorsqu'il s'agit de fichiers hiérarchiques autres, le connecteur intégré qui est un pilote JDBC, peut lire ou écrire des fichiers de longueur délimitée ou fixe et peut gérer les événements à l'intérieur d'une même ligne (longueur variable du même type de ligne).
Une fois que la description du fichier a été faite, il est possible d'effectuer de simples commandes SQL pour lire le fichier comme s'il était composé de plusieurs tables (voir l'image ci-contre)
2. Lire et écrire la donnée hiérarchique de manière efficace
Lecture / chargement de données hiérarchique avec Stambia
Le mapping universel de Stambia fournit la meilleure façon de lire des fichiers complexes afin de charger plusieurs cibles, avec un niveau de performance très élevé.
En effet, l'approche "multi-cibles" du mapping reste simple, tout en permettant de charger des cibles multiples à partir d'un seul fichier. Les fichiers seront chargés en une seule fois, mais les données seront envoyées en même temps (ou selon la séquence demandée) dans plusieurs cibles.Cela fournit un niveau élevé de performances pour lire, utiliser et transformer des données hiérarchiques sources.
Cette approche est aussi orientée données (data-centric). Elle permet à l'utilisateur de se concentrer sur le lien entre ses données et non sur le processus technique qui est nécessaire à la réalisation du mapping.
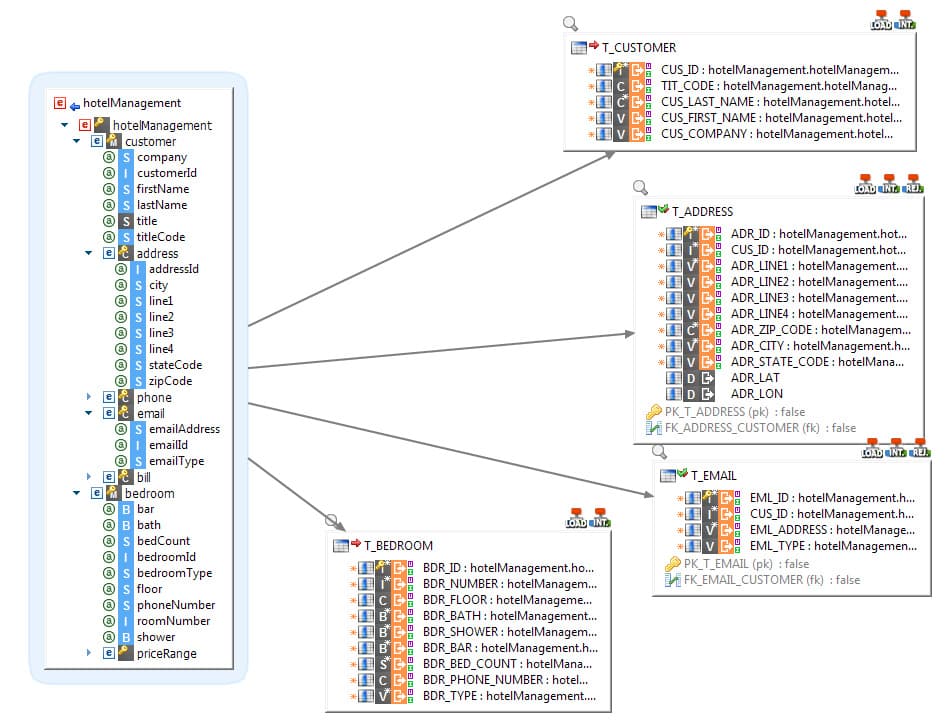
Ecriture de données hiérarchiques avec Stambia
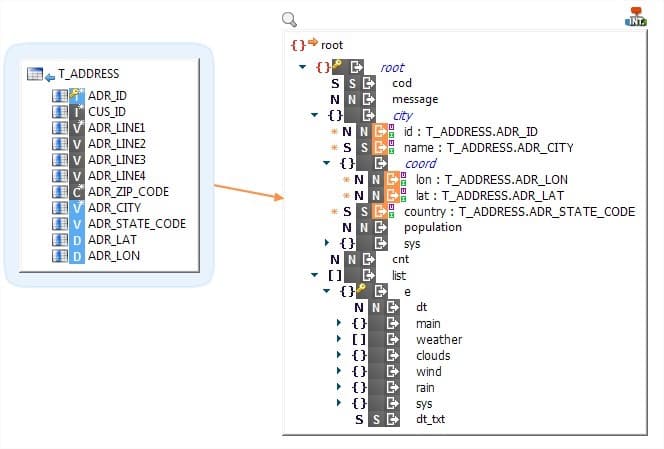
Stambia peut intégrer les données dans un fichier ou structure hiérarchique en un seul mapping et ce quelle que soit la complexité de la structure adressée.
Dans l'exemple ci-contre, la cible du mapping est un fichier XML, composé de plusieurs hiérarchies.
Tout en restant lisible, un seul mapping permettra de produire un fichier hiérarchique unique, pouvant contenir des hiérarchies très profondes, ou bien contenir de multiples occurrences de mêmes éléments, ou bien encore des hiérarchies juxtaposées.
Comme précédemment pour la lecture des données, cette approche est orientée données (data-centric). Elle permet à l'utilisateur de se concentrer sur le lien entre ses données et non sur le processus technique qui est nécessaire à la réalisation du mapping.
Cette approche est très utile également lors de l'usage de Web Services ou API qui utilisent ce type de données hiérarchiques pour les inputs ou les outputs.
3. Automatiser et industrialiser avec Stambia ETL
Industrialiser la lecture ou l'écritures de fichiers dans des répertoires
La manipulation de fichiers nécessite parfois l'itération des mêmes opérations sur plusieurs fichiers identiques.
Par exemple, lire plusieurs fichiers identiques en source et itérer : plusieurs commandes ou lots de commandes à intégrer dans un ERP ou CRM. Ou bien encore générer plusieurs fichiers à partir d'un même ensemble de données source : générer un fichier par ville ou par fournisseur.
Ces opérations peuvent se révéler complexes avec des solutions traditionnelles.
Stambia propose de nombreuses fonctionnalités qui automatisent ces processus, notamment la possibilité dans un mapping de gérer le niveau répertoire ou fichier afin d'automatiser (sans processus technique supplémentaire) la lecture ou l'écriture en lot de structures hiérarchiques.
Cette approche permet de garder une vision orientée métier (data-centric) des développements, et surtout de garantir des performances optimales lors du traitement de batch de fichiers importants.
Répliquer des données hiéararchiques (XML, JSON, Avro…) automatiquement

L'intégration de fichiers sources dans une cible peut aussi être automatisée en utilisant le composant de réplication.
Ce composant permet de parcourir un répertoire et d'intégrer massivement des fichiers dans une base de données relationnelle ou tout autre cible structurée.
Dans ce cas, il n'y a pas de mapping ni de développement. Le réplicateur est capable de créer une structure relationnelle (ou autre) à partir d'une structure hiérarchique de fichier et de compléter la base de données avec des fichiers qui ont été trouvés dans le dossier.
Ce type de composant peut incorporer des mécanismes d'intégration incrémentale (avec calcul des différences) pour intégrer de manière cohérente et sans doublons des données dans une cible.
Spécifications techniques
| Spécification | Description |
|---|---|
|
Architecture simple et agile |
|
|
Protocole |
HDFS, GCS, Azure Cloud HTTP REST / SOAP |
|
Format de données |
XML, JSON, AVRO, et tout format spécifique ASCII, EBCDIC, Montants packés, Parquet, ... |
| Connectivité |
Vous pouvez extraire ou intégrer des données de :
Pour plus d'informations, consulter notre documentation technique |
| Connectivité technique |
|
|
Caractéristiques standard |
|
| Caractéristiques avancées |
|
| Pré-requis techniques |
|
| Déploiement Cloud | Image Docker disponible pour les moteurs d'exécution (Runtime) et la console d'exploitation (Production Analytics) |
| Standard supportés |
|
| Langage de Scripting | Jython, Groovy, Rhino (Javascript), ... |
| Gestionnaire de sources | Tout plugin supporté Eclipse : SVN, CVS, Git, ... |
Vous souhaitez en savoir plus ?
Consultez nos différentes ressources


Vous n’avez pas trouvé ce que vous souhaitez sur cette page ?
Consultez nos autres ressources :

eBook : La gestion des formats de données hiérarchiques en toute simplicité
Livre Blanc : Comment manipuler les données hiérarchiques en toute simplicité
Stambia annonce son rapprochement avec Semarchy.
La solution Stambia devient Semarchy xDI Data Integration