
Stambia composant pour Big Data Hadoop
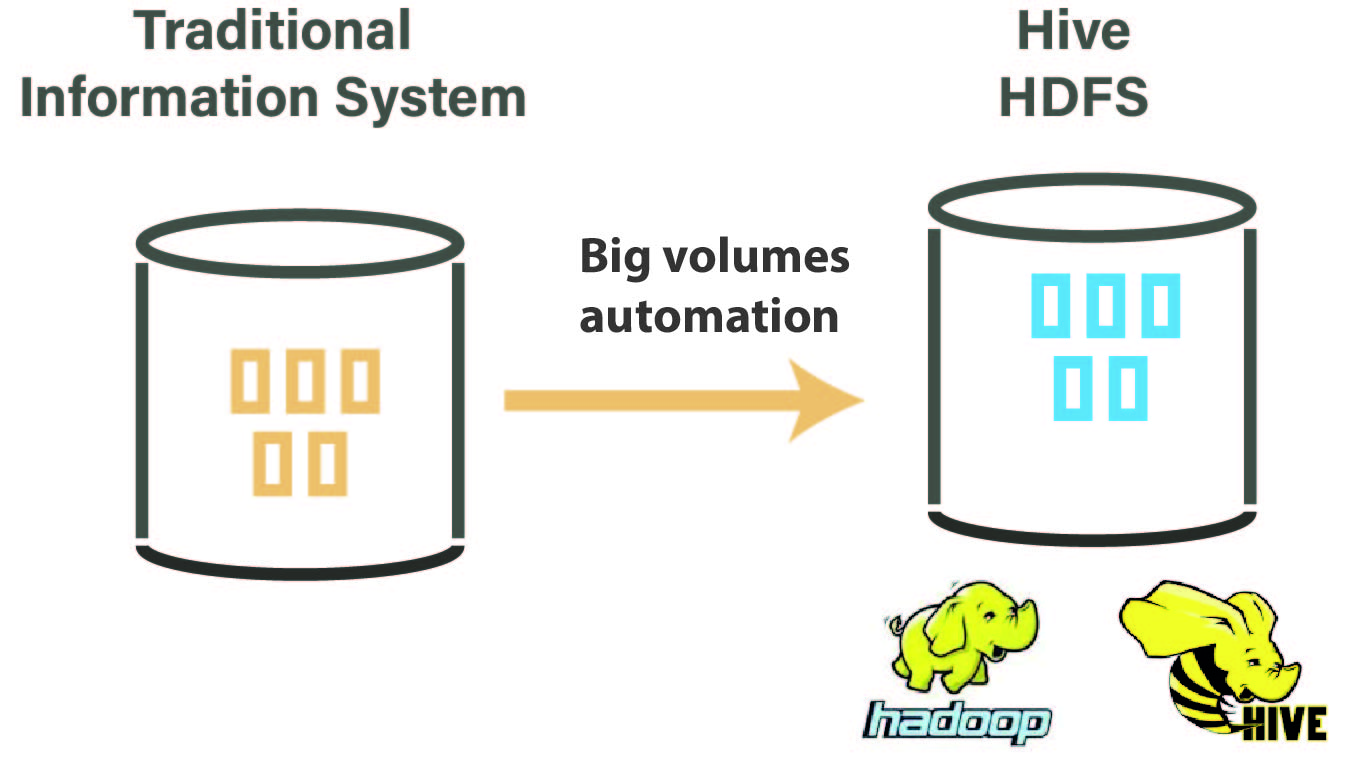
Apache Hadoop est un framework open source de stockage distribué et de traitement de très grands ensembles de données sur des clusters d’ordinateurs. L'écosystème Hadoop consiste en une collection de logiciels, chacun répondant à un besoin précis. Les principaux sont : HDFS, HBASE, Hive, Impala, Sqoop et bien d'autres encore.
L'intégration des données dans l'écosystème Hadoop est généralement adoptée pour gérer de gros volumes de données et une grande variété de données. L'utilisation des outils appropriés à cette fin est essentielle pour une mise en œuvre réussie.

Adopter Hadoop : les points clés
Les défis avec Hadoop
De nombreuses entreprises ont souvent du mal à passer aux plates-formes basées sur Hadoop. Voici quelques raisons :
- Des compétences inadéquates pour mettre en œuvre des stratégies logicielles et matérielles
- Un manque d’outils permettant de réduire le codage manuel ainsi que la redondance des efforts nécessaires à la mise en place de processus d’intégration
- Une courbe d'apprentissage plus longue pour l'équipe existante notamment la formation à la plateforme Hadoop
- Incapacité à utiliser efficacement la plate-forme pour réduire les coûts et optimiser les performances
- Risque d'exposition de données sensibles et confidentielles en raison de l'absence de processus de confidentialité des données
Pour surmonter ces difficultés, il est important de choisir les bons outils pour mener à bien vos projets. Ces derniers doivent réduire le codage manuel et automatiser les flux de travail, afin de simplifier l'exploitation et la maintenance.

Exploitez la puissance de Hadoop

Les outils traditionnels, bien qu’ils fournissent les fonctionnalités permettant de travailler avec la plate-forme Hadoop, n'étant pas conçus à l’origine pour traiter de large volume de données. Ils se sont adaptés pour fournir un composant ELT-isé pour l'intégration Hadoop.
La plateforme Hadoop, évolue de manière linéaire et prend en charge un large éventail de techniques de traitement analytique.
Lors de l’intégration de vos données dans hadoop, il est important d’utiliser une solution ELT pure capable de tirer le meilleur parti de ces fonctionnalités pour obtenir les meilleures performances.
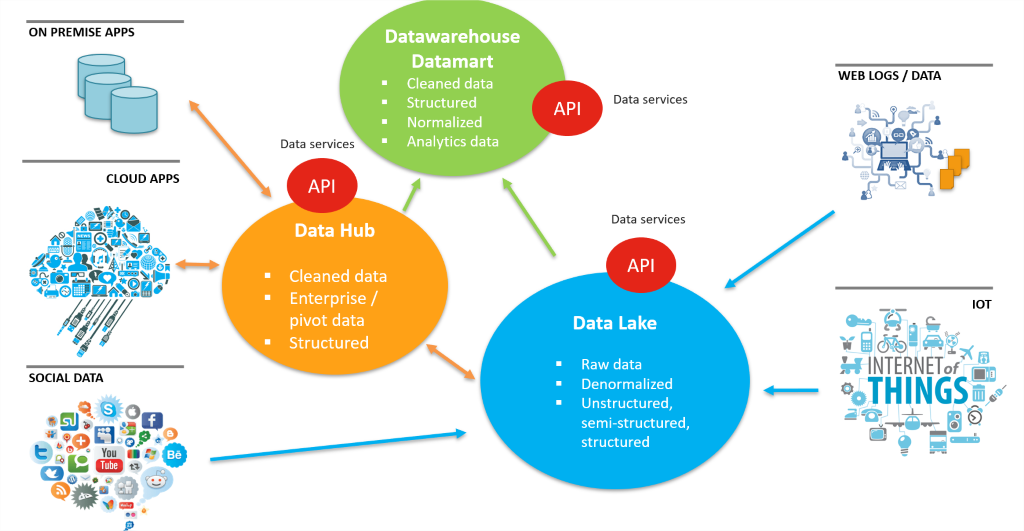
Projets de Datalake basés sur Hadoop
Les initiatives Data Lake impliquent de traiter une plus grande taille et une plus grande diversité de données provenant de divers types de sources. De plus, ces données doivent ensuite être traitées, réutilisées. Hadoop est devenu la plate-forme la plus utilisée permettant aux entreprises de créer un Data Lake.
Avec une grande variété de logiciels open source dans l’écosystème Hadoop, les équipes informatiques peuvent configurer l’architecture de Data Lake. Une partie essentielle consiste à configurer les pipelines d’intégration, qui alimentent le Data Lake. Les couches d'intégration doivent pouvoir répondre à différents besoins de données, en termes de volume, de variété et de vitesse.
La capacité de gérer différents types de formats de données, de technologies de données et d'applications est très importante.
Le meilleur scénario est celui où il ne faut pas empiler les couches d'intégration et conserver un solution unique cohérente et simple à gérer.
Problème de sécurité de données

L’adoption d’Hadoop étant en hausse, de plus en plus d’organisations ressentent le besoin de disposer de davantage de fonctionnalités de sécurité, étant donné que l’objectif initial était de traiter et de traiter de gros volumes de données.
Avec l'introduction du modèle de distribution commerciale par des éditeurs de logiciels tels que Cloudera, nous pouvons voir plus de fonctionnalités de sécurité ajoutées. Des modifications importantes ont été apportées à l'authentification Hadoop, avec Kerberos, où les données sont chiffrées dans le cadre de l'authentification.
L’intégration des données doit non seulement tirer parti de ces fonctionnalités de sécurité, mais également offrir une grande variété de solutions pour gérer des réglementations telles que le GDPR permettant le masquage des données dans Hadoop.
TCO de vos implémentations Hadoop
Outre la possibilité de traiter une grande variété de données, l'un des principaux avantages du passage à un écosystème Hadoop réside le coût par rapport aux systèmes de base de données traditionnels.
Dès lors, cela devrait également s'appliquer aux outils d'intégration qui seraient utilisés, afin de mieux contrôler le coût global des projets.

Principales caractéristiques du composant Stambia pour Hadoop
Le composant Stambia pour Hadoop offre diverses fonctionnalités permettant aux utilisateurs d’intégrer leurs données et de passer facilement à des plateformes basées sur Hadoop. Aucun codage manuel n’est requis et, avec l’utilisation du Designer, les utilisateurs peuvent effectuer des mappings de données de la même manière qu’ils le font avec n’importe quelle autre technologie, comme lors de l'utilisation d'une base de données, d'un fichier XML ou JSON, de fichiers plats, etc.
Cela est possible grâce aux modèles Hadoop conçus spécifiquement pour chaque logiciel de l'écosystème Hadoop. Ces modèles réduisent non seulement le besoin d'écrire des codes manuels, mais ils permettent également de faire évoluer les processus d'intégration avec le temps.
-
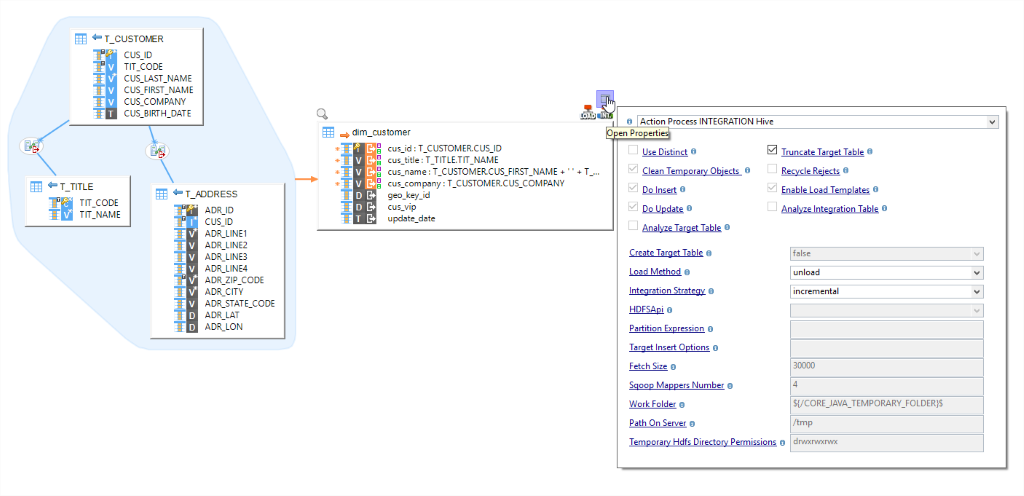
HDFS – Il est très important d’automatiser le processus de transfert de gros volumes de données vers le système de fichiers distribués Hadoop. En quelques gouttes, vous pouvez le faire dans Stambia, à l’aide de modèles HDFS, qui peuvent vous aider à déplacer des données vers et de HDFS. Ces modèles peuvent être connectés n'importe où en fonction des exigences d'intégration, par exemple. SGBDR vers HDFS, HDFS vers Apache Hive, etc.
-
HIVE – Mappages de conception pour déplacer les données vers et à partir de Hive de la même manière que vous le feriez dans le cas d'un SGBDR. Effectuez des opérations HiveQL et choisissez des options de modèle rapide pour décider de la stratégie d'intégration et des méthodes optimisées.
-
HBASE – Travaillez facilement avec la base de données NoSQL. Pas de connaissances pratiques spécialisées pour commencer, car les modèles Stambia pour HBASE prennent en charge toutes les complexités. En tant qu’utilisateur, vous fournissez simplement les glisser-déposer et choisissez la stratégie d’intégration, ou extrayez des données hors de HBASE en effectuant des jointures rapides par un simple glisser-déposer.
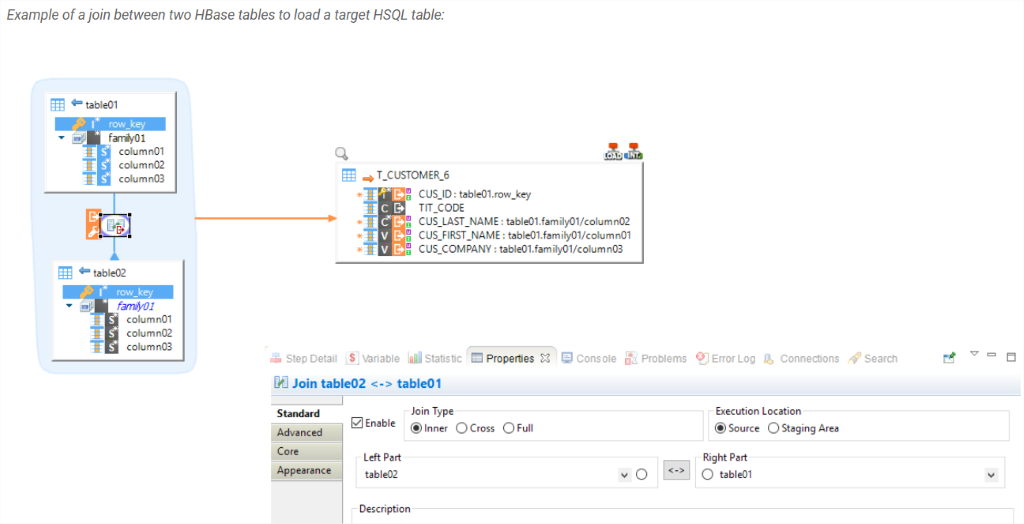
En dehors de ceux-ci, une multitude de modèles dédiés pour Sqoop, Cloudera Impala, Apache Spark, etc. sont disponibles pour que les utilisateurs puissent définir leur processus d'intégration en utilisant les logiciels appropriés de leur écosystème Hadoop.
Stambia: approche dirigée par les modèles pour augmenter la productivité, l'approche ELT pour augmenter la performance
Stambia, étant un pur outil ELT, convient à la configuration de processus d’intégration lorsque vous travaillez avec l’écosystème Hadoop. Stambia apporte une approche basée sur les modèles, qui aide les utilisateurs à automatiser de nombreuses étapes redondantes impliquant l’écriture manuelle de code. De cette façon, les utilisateurs se connectent et travaillent avec leurs métadonnées, conçoivent des mappings simples et choisissent certaines configurations / options. Lors de son exécution, le code est automatiquement généré sous forme native et exécuté.
Les modèles contenant le code complexe sont accessibles à l'utilisateur et peuvent être modifiés / améliorés à tout moment sans aucune contrainte.
En résumé, vous utilisez un outil qui non seulement accélère votre configuration d’intégration, raccourcit votre cycle de développement, mais vous fournit également une plate-forme d’intégration pouvant être adaptée à tout changement technologique ou de processus métier.

Stambia: une solution unifiée pour vos projets Data Lake
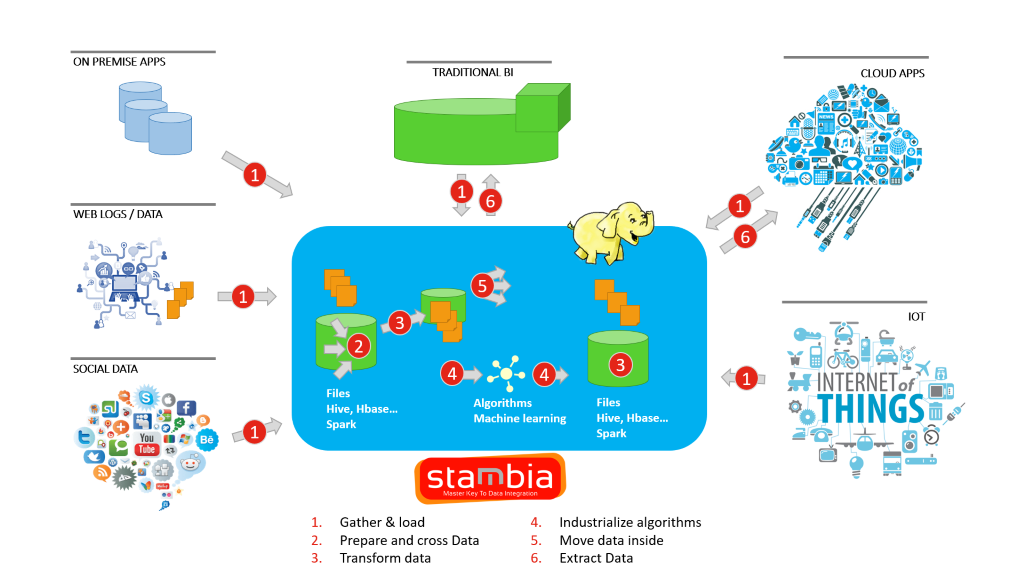
Stambia est une solution unifiée qui aide avant tout les organisations et leurs équipes informatiques à construire la couche d'intégration sans faire face à de multiples logiciels et solutions, avec différentes méthodes de conception et diverses implications en termes de licences.
Etant donné que dans un Data Lake, il est nécessaire d’intégrer différents types de données structurées, semi-structurées et non structurées, en utilisant une seule plate-forme d’intégration, l’accent reste mis sur l’architecture Data Lake, plutôt que sur les complexités inhérentes à une intégration multiple. solutions.
Stambia offre également la flexibilité nécessaire pour personnaliser toute technologie open source ou autres exigences.
Stambia: l'intégration en toute sécurité
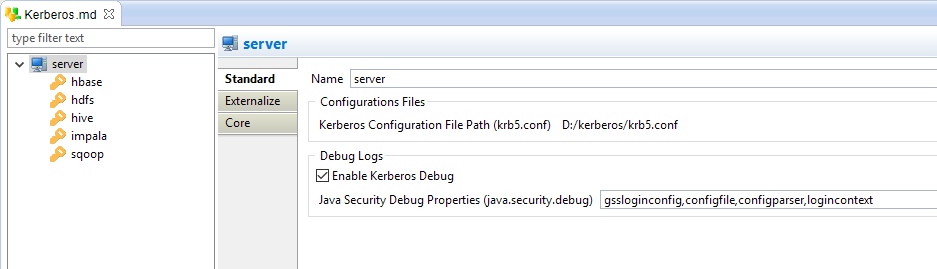
Les composants Stambia pour Hadoop prennent en charge l’authentification Kerberos et sont faciles à installer sur n’importe laquelle des technologies en un simple glisser-déposer. Toutes les propriétés Kerberos peuvent être définies de manière à avoir un accès sécurisé aux données dans Hadoop lors de l’intégration.
Un autre aspect est la protection de la confidentialité des données, ou règlement GDPR, qui devient très importante pour de nombreuses organisations. Stambia a un composant pour le GDPR, où les utilisateurs peuvent annonymiser et pseudonymiser leurs données.
Pour en savoir plus sur la protection des données à caractère personnel, regardez notre vidéo sur l'outil Stambia Privacy Protect :

Hadoop est une plateforme peu coûteuse, la couche d'intégration doit l'être aussi
À la fin, le coût de la couche d’intégration avec Stambia dans vos projets Big Data restera transparent et facile à comprendre. Le modèle de tarification de Stambia reste assez simple et indépendant du type de projets, des volumes de données, du nombre d’environnements, etc.
En tant que E-LT, Stambia ne nécessite aucun matériel spécifique et, en raison de sa simplicité d’utilisation, la courbe d’apprentissage est très courte. Par conséquent, dans vos projets Big Data basés sur Hadoop, vous avez une visibilité claire de votre coût total de possession.

Spécifications et pré-requis techniques
| Spécifications | Description |
|---|---|
|
Protocole |
JDBC, HTTP |
|
Données structurées et non structurées |
XML, JSON, Avro (disponible prochainement) |
|
Technologies Hadoop |
Les connecteurs Hadoop suivants sont disponibles:
|
| Connectivité |
Vous pouvez extraire les données de :
Pour plus d'informations, consulter notre documentation technique
|
|
Stockage |
Les opérations suivantes peuvent être effectuées sur des répertoires HDFS:
|
| Performance du chargement des données |
Les performances sont améliorées lors du chargement ou de l'extraction de données via un ensemble d'options sur les connecteurs, ce qui permet de personnaliser le traitement des données, en choisissant notamment les chargeurs Hadoop à utiliser. Pour améliorer les performances, les connecteurs prennent en charge l'utilisation de divers utilitaires, tels que le chargement de données dans Apache Hive ou Cloudera Impala directement à partir de HDFS, de Sqoop, via JDBC, ... |
| Version du Designer Stambia | À partir Stambia Designer s18.3.8 |
| Version du Runtime Stambia | À partir Stambia Runtime s17.4.7 |
| Notes complémentaires |
|
Vous souhaitez en savoir plus ?
Consultez nos différentes ressources



Vous n’avez pas trouvé ce que vous souhaitez sur cette page ?
Consultez nos autres ressources :
- [Techno] Le Mapping Universel Stambia
- [Techno] L'approche ELT
- [Techno] L'approche par les modèles
- [Techno] Le concept de plateforme adaptive
- [Solution] Comprendre l'architecture Data Hub
- [Produit] Composant Salesforce
- [Produit] Publier et consommer des API et Microservices
- [Produit] Composant Stambia pour le Cloud
Stambia annonce son rapprochement avec Semarchy.
La solution Stambia devient Semarchy xDI Data Integration